.png)
Containers Anatomy 101: What is a Cluster?
From anetworking perspective,containers extend the network "edge"the boundary between network forwarding decisions and a packet reaching itsfinal destinationdeep intoahost. Theedge is no longer the network interface ofahost butis instead several layers deep into logical constructswithinahost. And the network topology is abstracted and reaches deep into these logical constructs withinahost, in the form ofoverlay network tunneling, virtual interfaces, NAT boundaries, loadbalancers, and networking plugins. Network andsecurity architects can no longer ignore OS internals when designing their architectures. Containers forcethese architectures tounderstandwhere a packet goes after it passes through a host's NIC.
Orchestration Systems
With that said, an orchestration system is required to bring some form of order into containers environments.Anorchestration system manages the details around organizing, scaling,andautomatingcontainers, and creates logical constructs around various componentsthatare relevant tocontainer behavior.Theyare alsoresponsible for organizing logical boundaries associated with containerruntimes andcreating logical constructsthat can be assigned an IP address. That said, such systems areexternalandcannot actually deploy and manage the lifecycle of specificcontainers runtime instances, which arestill handled by Docker, for example.
There are manycontainersorchestration systems, but the two most commonly usedtodayare Kubernetes and OpenShift. They both accomplish the same basic goals, with the primary difference being that one is aproject and the other is aproduct: Kubernetes is a project born largely out of Google, and OpenShift is a product owned by Red Hat. Generally speaking, Kubernetes is most often seen inpubliccloud environmentsand OpenShift is most often seen in on-premisedatacenters, but there is a significant amount of overlap betweenthe two.In short, Kubernetes underlies both approaches, with some slight difference in terminology between each.
A Brief HistoryofContainers
Believe it or not, containerspre-date Kubernetes. Docker, for example, first released their containers platform in 2013, whereas Kubernetes did not releasetheir public cloud-focusedprojectuntil 2014. OpenShiftlaunchedbefore both, with a focus on hosts deployed inon-premise data centers.
Simply deploying container runtimes on a local host generally meets developers needs, sinceruntimes can communicate with each othervia "localhost" and unique ports. Container runtimes arent assigned specific IP addresses. If you are focused on writing fast and efficient code and deploying your application across a collection of associated container runtimes, thisapproachworks fine. But if you want that application to access external resources outside of the local host, or if you want external clients to access that application, you cannot ignore networking details. This is one of the reasons an orchestration system is needed.
Kubernetes was created around a set of building blocks and an API-driven workflow toorganize the behavior of container runtimes.In this approach, Kubernetes createsa series of logical constructs within and across hosts associated with a specific containerizedenvironment, andcreatesa whole new set of vocabulary to refer to these constructs.While Kubernetes applies these building blocks and API-driven workflowsaround a set ofcompute metrics associated with CPU allocation, memory requirements,andother metrics such as storage, authentication, and metering, most security and networkingprofessionalsare focused on one thing:
What boundaries does an IP packet pass through as it is en route to some logical construct that is assigned an IP address?
From anetworking perspective, both Kubernetes and OpenShift create logical, relevantconstructs in a hierarchical approach, with only a slight difference in vocabulary between each system. This is illustrated below.
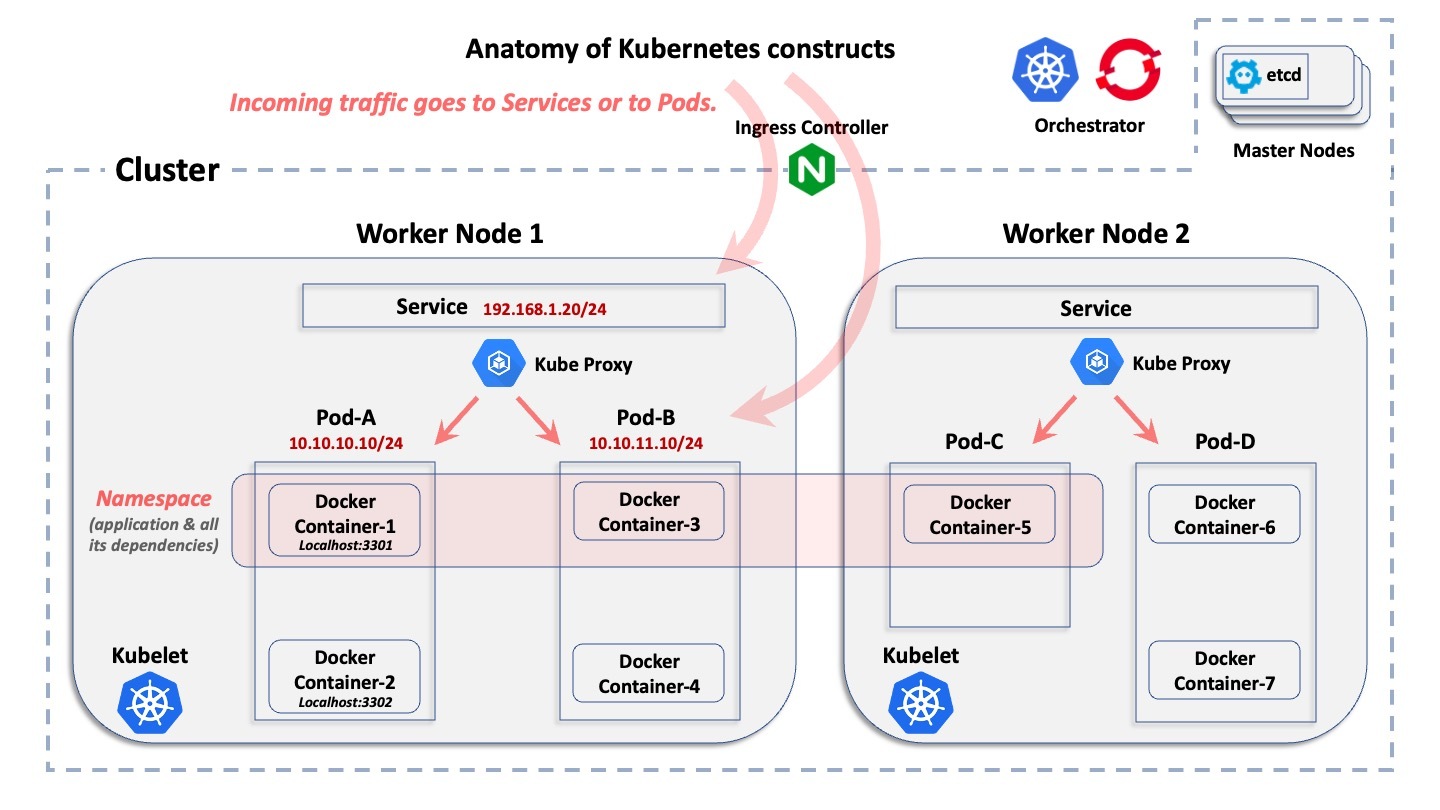
The ABCs ofaContainersCluster
This diagram shows the basic logical construct of a Kubernetes environment. It doesnt explain what each construct does,butonlyhow they logically relate to each other.
Starting from the broadest construct down to the smallest,here are quick explanations:
- Cluster:Acluster is the collection of hosts associated with a specificcontainerized deployment.
- Nodes:Inside of acluster, there arenodes. Anode is the host on whichcontainers reside. A host can be either a physical computer or a VM, and it can reside in either an on-premdatacenter or inapubliccloud. Generally, there are two categories ofnodes in a cluster: the masternodes and the workernodes. To oversimplify things, amasternode is the control plane that provides the central database of the cluster and the API server. Theworkernodes are the machines running the real applicationpods.
- Pods:Inside of eachnode, both Kubernetes and OpenShift createpods. Eachpod encompasses either one or morecontainer runtimesandismanaged by theorchestration system. Pods are assigned IP addresses by Kubernetes and OpenShift.
- Container:Inside ofpods are wherecontainer runtimes reside. Containers within a givenpod all share the same IP address as thatpod, and they communicate with eachotherover Localhost, using unique ports.
- Namespace:A given application is deployed "horizontally" over multiplenodes in a cluster and defines a logical boundary to allocate resources and permissions. Pods (and therefore containers)andservices, but alsoroles,secrets,and many other logical constructs belong to anamespace.OpenShift calls this aproject, but it is the same concept. Generally speaking, anamespace maps to a specific application, which is deployed across all of the associatedcontainers within it. Anamespace has nothing to do with a network and security construct (different from a Linux IP namespace)
- Service:Sincepods can be ephemeralthey can suddenly disappear and later be re-deployed dynamicallyaservice is a front end,which is deployed in front of a set of associatedpodsand functionslike a load-balancer with a VIPthatdoesn't disappear if apod disappears. Aservice is a non-ephemeral logical construct, with its own IP address. With only a few exceptions within Kubernetes and OpenShift, external connections point toa services IP address and are then forwarded to backendpods.
- Kubernetes API Server:This is where the API workflow is centralized, with Kubernetes managing the creation and lifecycle of all of these logical constructs.
SecurityChallenges with Containers
In order to create security segments along workload boundaries, it'snecessary to understand these basic logical constructscreated by Kubernetes. External network traffic moving in and out from the hosted application will generally not be pointing to the IP address of the underlying host, thenode. Instead, network traffic will be pointing to either aservice or apod within that host. Therefore, a workload's associatedservices andpods need to be sufficiently understood in order to create an effective segmentation security architecture.
Interested inmore? Check out our paper onthe challenges of network-based approaches to container segmentation and how to overcome them using host-based segmentation.


